研究
人工知能と深層学習
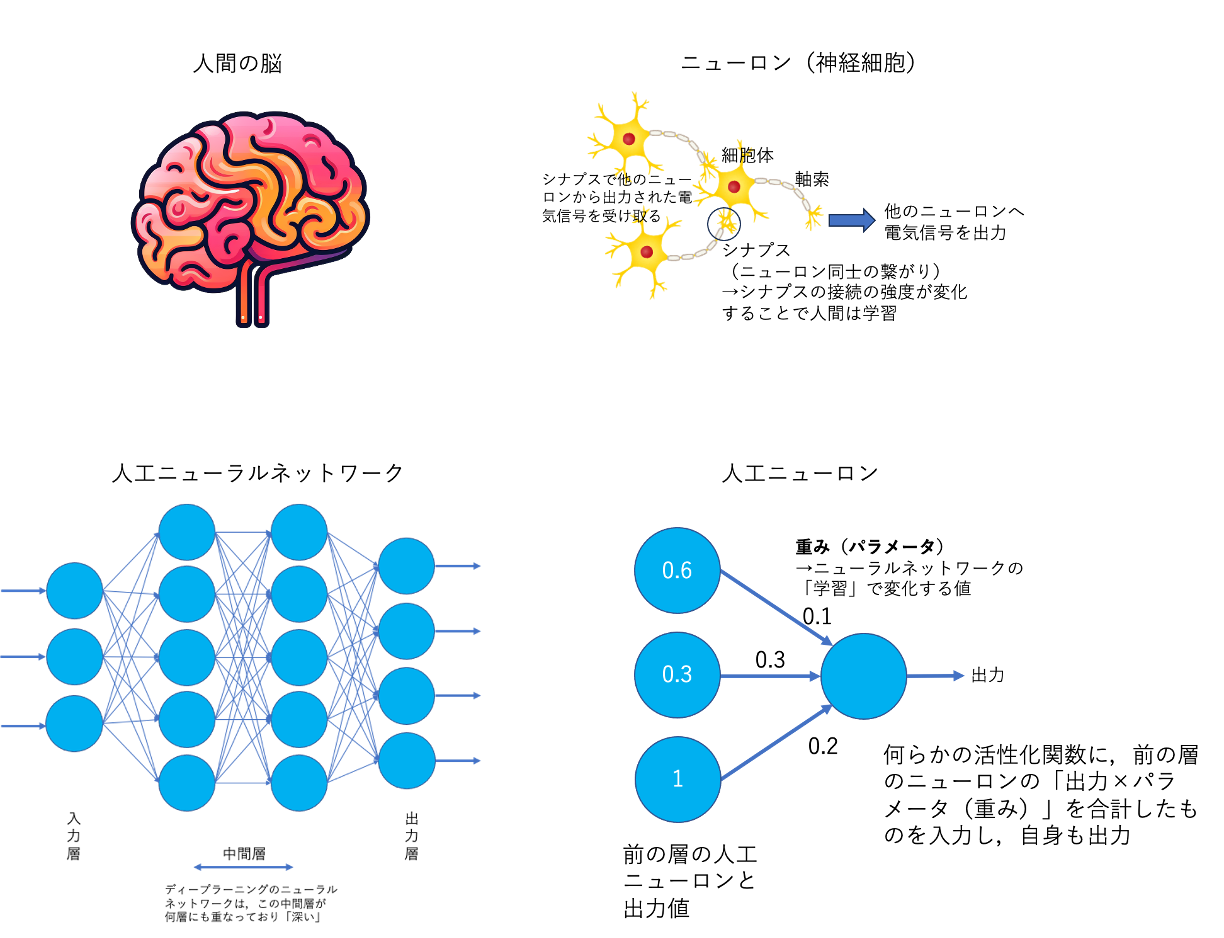
「人工知能(AI,Artificial Intelligence)」の研究にはさまざまな分野が存在し,1956年にAIという概念が生まれて以降,第1次AIブームの探索,第2次AIブームの知識表現・エキスパートシステム,第3次AIブームの深層学習(ディープラーニング,deep learning)などさまざまな手法が提案されてきました. 特に第3次AIブームで注目されている深層学習は,画像認識,自然言語処理,意思決定や制御,科学的発見などの分野で驚異的な性能を見せ,それ以前のブームの手法とは一線を画した影響をもたらしています.機械が,何らかのルールや知識を事前に決定しておくのではなく,経験(データ)によって,知識,性能を改善する手法は機械学習(machine learning),その中でも人間の脳を模倣した人工ニューラルネットワークを利用し,その層が非常に深いものを使う手法を深層学習と呼びます. 近年はChatGPTをはじめとする「生成AI」の登場によって第4次AIブームとも称される状況になっています.
私は第3次AIブームの深層学習以降にAIに興味を持ち,深層学習をベースとした手法,特に強化学習が関わる分野を中心に研究をおこなっています.
【キーワード】
- 人工知能(AI, Artificial Intelligence)
- 深層学習(deep lerning)
- 機械学習(machine learning)
- ニューラルネットワーク(neural networks)
- 生成AI(Generative AI)
- ChatGPT
強化学習と深層強化学習
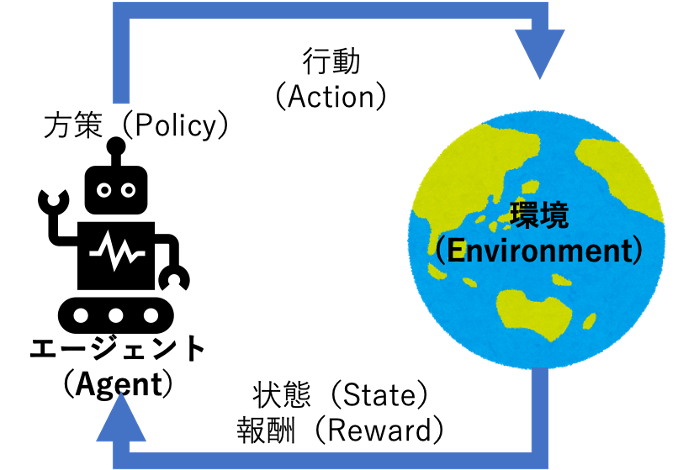
強化学習は,人工知能分野の中でも,特に人工知能の意思決定に関わる手法です.強化学習は,意思決定の主体であるエージェント(Agent)が環境(Environment)と相互作用しながら,環境からの報酬を最大化するような行動を学習する手法です. ここで,エージェントとは意思決定を行うAIそのものを指します.環境とは何らかの解きたい課題が存在し,エージェントが行動する場所,つまりゲームそのものであったりロボットが置かれた作業場などを指します.報酬とは,エージェントが環境内で実行した行動が,どれだけ課題の成功に貢献したかを示す値であり ,環境からこの報酬を多く受け取れるように学習,つまり強化学習を行うことで,我々人間が指定した課題をこなせるAIを作ることができます.このようなエージェントの行動の意思決定則は方策(policy)と呼ばれ,この方策が学習によって変化します. 深層強化学習は,深層学習をベースとした強化学習手法で,深層学習のニューラルネットワークを方策モデルとして用いる手法です.深層強化学習の登場以前は,強化学習で解ける課題は限定的でしたが,深層強化学習の登場によって,より複雑な課題を解くことが可能になりました. 例えば,Atariゲームなどで人間のエキスパート並みのプレイができるDQN(Deep Q-Networks)とその派生手法,囲碁の世界チャンピオンを倒したAlphaGoや不完全情報ゲームのRTSゲーム「スタークラフト2」でグランドマスターに勝利したAlphaStar等のゲームAI,ロボット制御,その他にも行列計算アルゴリズムの発見や半導体の設計,近年では生成AIの出力を人間の価値観に合わせて調整するAIアライメントなど,応用範囲は広範にわたります.
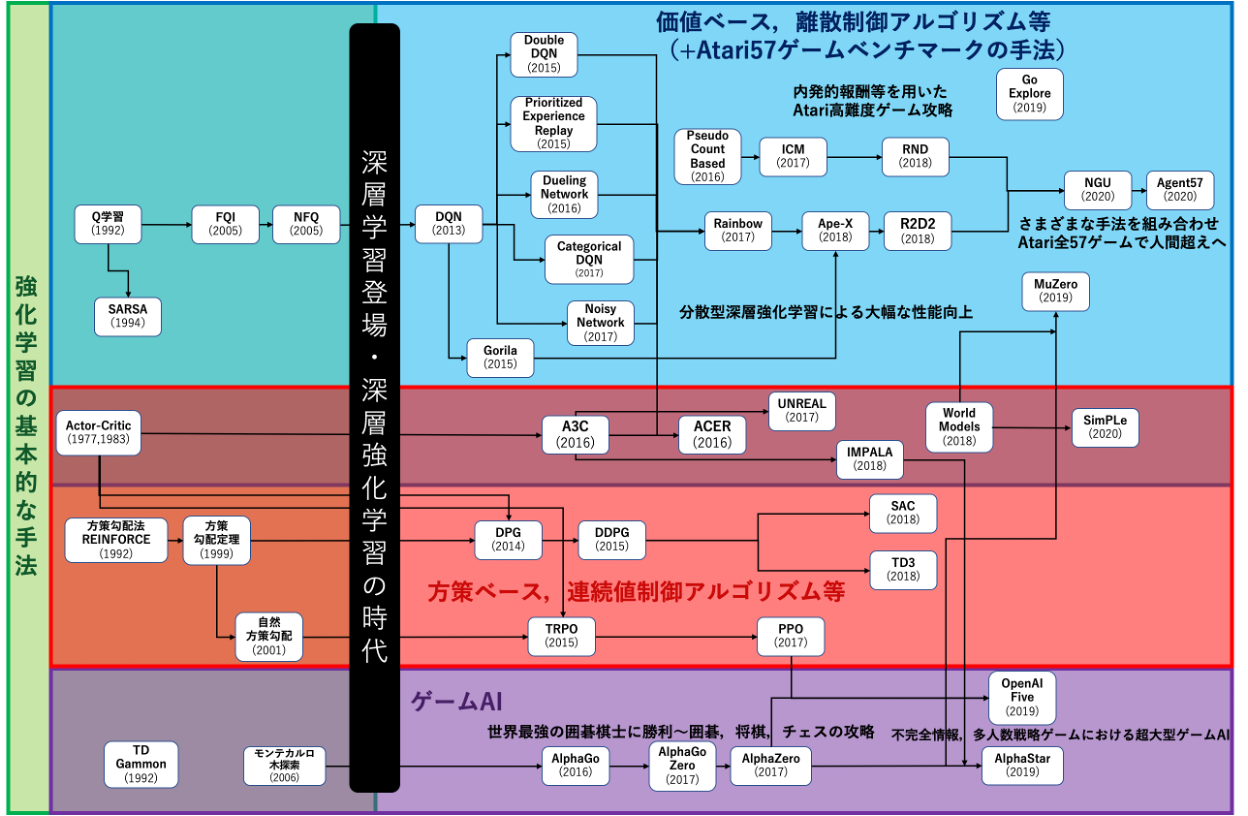

「強化学習の基礎と深層強化学習 東京大学 松尾研究室 深層強化学習サマースクール講義資料」
その他,私たち東京大学松尾研究室をはじめとする有識者で翻訳した,R.Suttonらによる「Reinforcement Learning: An Introduction」(邦訳書名:強化学習(第2版))は,世界的に有名なバイブルともされる強化学習の教科書です.内容は少々専門的ですが,強化学習に必要な知識はこの本が網羅しており,強化学習の研究や専門家を目指すような方は通読をお勧めします.

【キーワード】
- 強化学習( RL, reinforcement learning)
- 深層強化学習(deep reinforcement learning)
- ベルマン方程式(bellman equation)
- 価値観数(value function)
- 行動価値観数(action value function)
- マルコフ決定過程(markov dicision process)
- 部分観測マルコフ決定過程(POMDP, partial ovservable markov dicision process)
- TD学習(temporal difference learning)
- Q学習(Q-learning)
- 方策勾配定理(policy gradient theorem)
- アクター・クリティック(actor-critic)
- モデルフリー学習,モデルベース学習(model free learning, model-based learning)
- AIアライメント(AI Alignment)
マルチエージェント学習・マルチエージェント強化学習
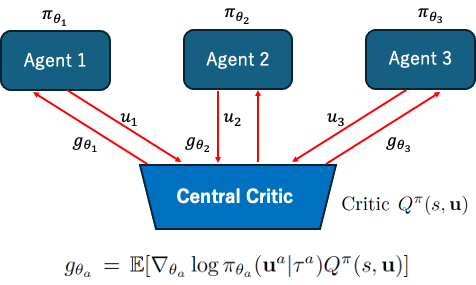
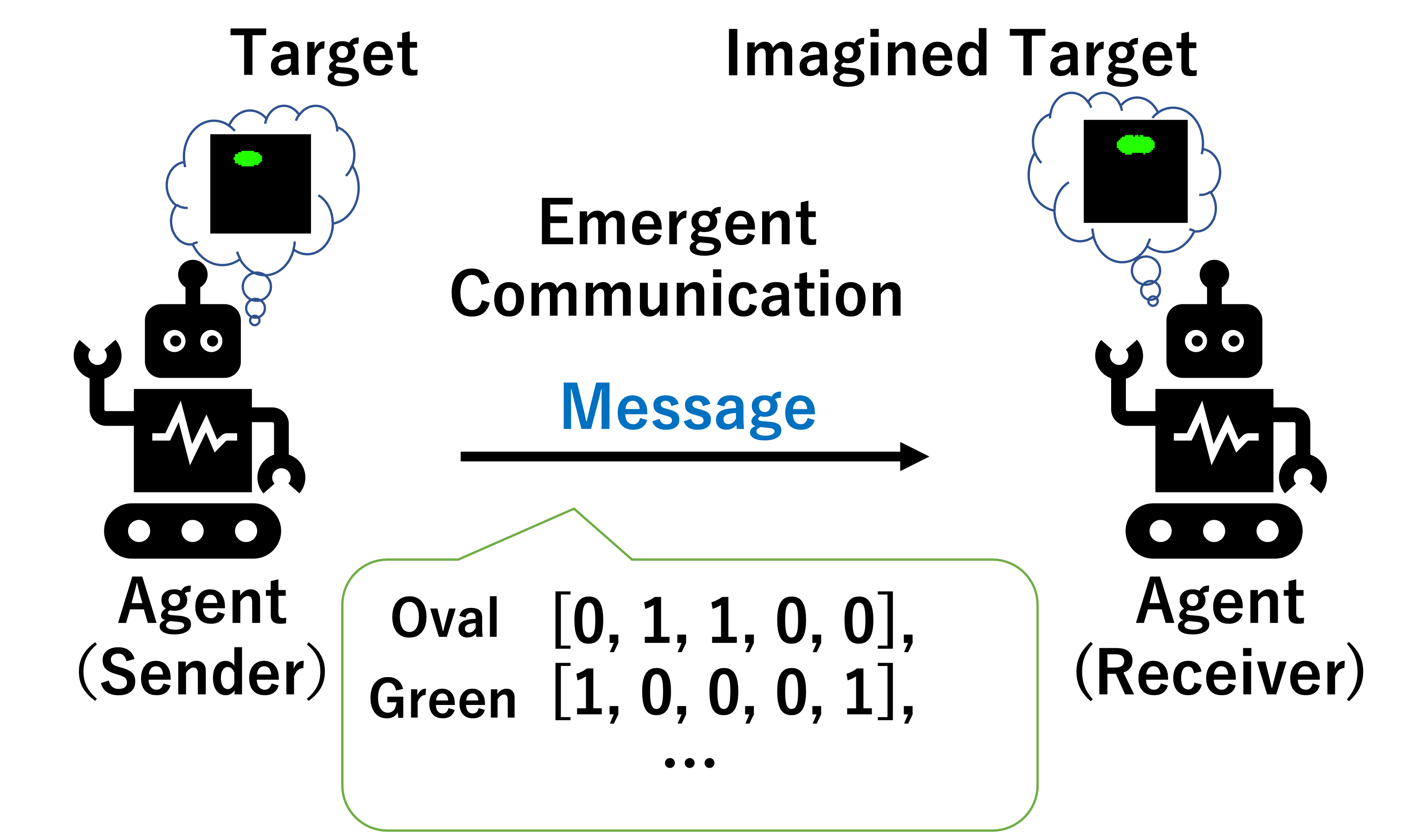
AI,つまりエージェントが環境内に多数存在し,それらのエージェントが協力,競争,交渉などを行うシステムをマルチエージェントシステム,その中でもエージェントが協調や競争のやり方を学習によって改善する手法をマルチエージェント学習,その学習手法に強化学習を用いるものを特にマルチエージェント強化学習と呼びます. 私は特にこのマルチエージェント強化学習に関する領域を専門としています.世の中の課題の多くは,人間か機械かに関係なく,意思決定能力を持った複数の主体が関わります.例えば交通システム,電力システム,スポーツ,経済活動,金融取引,政治,軍事戦略,もっと一般的なところでは人間同士の対話やお片づけなどもマルチエージェントな課題として扱うことができます. AIの発展に伴い,これらの課題にAIが入り込んでくることが予想されます.仮にそうでなくとも,AIを用いたシミュレーションで,人間が行うべき行動を決定したり,そもそもの人間の能力(例えば言語)の起源のヒントを得ることができます.マルチエージェント(深層)強化学習では,このようなマルチエージェントの課題に対し,深層強化学習という,現在最も協力な意志決定側の学習手法を持ち込み,その課題の解決を目指します.
これまでの研究では,大きく分けて,(1)マルチエージェント強化学習の協調的な学習における学習の効率化[1],(2)エージェント間のコミュニケーションの効率化およびそのコミュニケーションに利用される言語の分析を中心に行ってきました[2].
【キーワード】
- マルチエージェントシステム(MAS, multi-agent system)
- マルチエージェント学習(multi-agent learning)
- マルチエージェント強化学習(MARL, multi-agent reinforcement learning)
- 中央制御型学習分散型実行(CTDE, centralised training and distributed execution)
- IGM原理(individual global max principle)
- 他者モデリング(opponent modeling)
- 心の理論(theory of mind)
- コミュニケーション創発(emergent communication)
- 創発言語(emergent language)
- 構成性(compositionality)
- Lewisシグナリングゲーム(Lewis signaling game)
【論文】
[1]今井翔太, 岩澤有祐, 松尾豊, 動的なマルチエージェント環境におけるモデルメディエータを利用したモデルベース強化学習, 人工知能学会誌,Vol.38, No.5, pp.1-14,2023年
[2]今井翔太, 岩澤有祐, 鈴木雅大, 松尾豊, 異なる事前知識を持つ深層生成モデルを用いてメッセージ生成を行うエージェント間のコミュニケーション創発, 人工知能学会誌,Vol.39, No.2, pp1-14, 2024年
生成AI,大規模言語モデル
2022年末にOpenAI社がChatGPTを発表して以降,テキストの他,画像や動画像,音声なども含んだ幅広いコンテンツを生成できる「生成AI(Generative AI)」が注目を集めています. ChatGPTの学習には,人間のフィードバックに基づく強化学習(RLHF,Reinforcement Learning From Human-Feedback)と呼ばれる手法が用いられており,私の専門である強化学習が生成AIのコア技術となったことが興味を持つきっかけでした.
RLHFは,ChatGPTを含めた大規模言語モデル(LLM,Large Lungage Model)の出力,ひいては今後ますます性能が向上して人間並みかそれを超えると予想されるAIの行動を人間の価値観に合わせる「AIアライメント」と呼ばれる分野の技術として急速に発展しています. 昨今,生成AIの急速な性能発展により,人間と同等の知能を持つAGI(汎用人工知能,Artificial General Inelligence)や,人間の能力を上回るASI(超知能,Artificial Super Intelligence)の登場が現実視されており,いわばAIをコントロールする技術であるAIアライメントと強化学習は,今後AI研究の中でも重要な位置を占めることになると考えられます.
その他の生成AIの興味分野としては,「AIエージェント」と呼ばれる手法があります.生成AIブーム以降のAIエージェントは一般的に,ChatGPTのような言語出力ベースのAIが,ツール(例えば検索エンジンや計算機等)などを利用しながら,複雑な目標を自律的に解く手法をさします.生成AIは,それ単体では言語や画像を出力するだけに過ぎませんが,AIエージェントの方法論により,検索や計算機などの外部ツールを用いて,人間が与えたプロンプトから極めて複雑な目標を自動的に解決することができます. 最近では,複数のエージェントに役割を割り振って課題解決を行うマルチエージェント手法なども注目されており,生成AIの発展の鍵を握る分野の一つとなっています.
生成AIに関しては,技術的基礎や研究動向,その経済的・文化的影響,長期的な展望をまとめた『生成AIで世界はこう変わる』という書籍を2024年に出版しています.本書は,2024年最初に東京大学で最も売れた本となったほか,テレビ番組でも特集され,現在は生成AI関連の書籍で最も参照されている一冊となっています.こちらは一般向けの書籍であり,研究者やエンジニアのような専門家でなくとも,生成AIに必要な知識を全て学べる内容となっています.

【キーワード】
- 大規模言語モデル(LLM, large language model)
- トランスフォーマー(transformer)
- 自己注意機構(self-attention mechanism)
- スケーリング則(scaling law)
- チンチラ則(chinchilla law)
- 能力創発(emergent ability)
- 拡散モデル(diffucion model)
- 指示チューニング(instruction tuning)
- 教師ありファインチューニング(SFT, supervised fine-tuning)
- 人間からのフィードバックに基づく強化学習(RLHF, reinforcement learning from human-feedback)
- プロンプトエンジニアリング(prompt engineering)
- 文脈内学習(in-context learning)
- AIエージェント(AI-agent, LLM-agent)